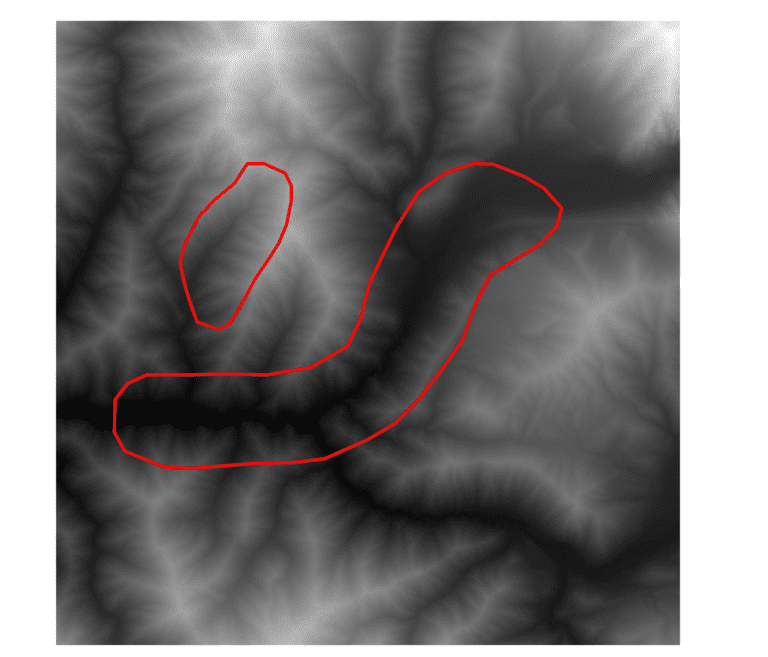
Zonal Statistics Algorithm with Python in 4 Steps
It is a common need to summarize information from a gridded dataset within an irregularly shaped area. While at first glance this may seem simple, reconciling differences between raster (gridded) and vector (polygon) datatypes can quickly become complicated. This article shows how to implement a zonal statistics algorithm in Python in 4 steps.
- Load raster data and vector polygons
- Rasterize polygon features
- Mask input data to polygon extent
- Calculate zonal statistics for the polygon extent
1. Load raster data and vector polygons
Start by importing the necessary Python modules.
import gdal # raster management import ogr # vector managment import numpy as np # gridded data import os # file managment import csv # for saving results in csv format
Now set the file paths for the raster and vector data and use gdal and ogr to load the raster and vector data, respectively. Access the layer which contains the polygon data from the vector data source that was loaded. Then get the GeoTransform information (positions the gridded raster data and specifies cell sizes) and no data value for the raster data.
fn_raster = "path/to/raster" fn_zones = "path/to/vector/polygons" # load rater and vector data r_ds = gdal.Open(fn_raster) p_ds = ogr.Open(fn_zones) # get vector layer lyr = p_ds.GetLayer() # get geotransform and no data for raster geot = r_ds.GetGeoTransform() nodata = r_ds.GetRasterBand(1).GetNoDataValue() zstats = [] # empty list to hold the zonal statistics once they are calculated
We’re also going to do a little more setup with gdal and ogr to prepare for determining the overlap between the raster grid and vector polygons. Let’s get gdal and ogr drivers to create temporary raster and vector layers in memory and set the name for a temporary shapefile.
mem_driver = ogr.GetDriverByName("Memory")
mem_driver_gdal = gdal.GetDriverByName("MEM")
shp_name = "temp"
2. Rasterize polygon features
Once the raster and vector data are loaded it’s time to determine where they overlap. This will be the most complicated and intensive part of the algorithm. To start, read the first polygon feature from the vector layer. Then start a while loop that will continue as long as there is another feature in the vector layer. Below is the basic way to set up the loop. This loop will be modified as we continue.
p_feat = lyr.GetNextFeature()
while p_feat:
p_feat = lyr.GetNextFeature()
We need to create some functions that will help us create a new raster to store the rasterized polygon features. These functions will make more sense when we call them with actual data. For now, add the function definitions at the top of the script. First we need to convert the convert the coordinates of the bounding box containing a polygon feature to cell coordinates, or offsets, (row and column numbers) that to correspond the input raster. The bounding box of a polygon is the rectangle that contains the entire polygon feature, it consists of minimum and maximum X and Y coordinates.
def boundingBoxToOffsets(bbox, geot):
col1 = int((bbox[0] - geot[0]) / geot[1])
col2 = int((bbox[1] - geot[0]) / geot[1]) + 1
row1 = int((bbox[3] - geot[3]) / geot[5])
row2 = int((bbox[2] - geot[3]) / geot[5]) + 1
return [row1, row2, col1, col2]
Next write a function that creates a new GeoTransform with the cell offsets that were calculated in the function above. These two functions will allow us to create a new, smaller raster that only covers the area overlapped by a polygon feature.
def geotFromOffsets(row_offset, col_offset, geot):
new_geot = [
geot[0] + (col_offset * geot[1]),
geot[1],
0.0,
geot[3] + (row_offset * geot[5]),
0.0,
geot[5]
]
return new_geot
Now comes the most complicated part of the algorithm: creating a new empty raster in memory and converting the polygon features to rasters. Follow the comments in code snippet below to understand what is accomplished by each line of code. You may also find it useful to review the GDAL and OGR documentation.
while p_feat:
if p_feat.GetGeometryRef() is not None:
if os.path.exists(shp_name):
mem_driver.DeleteDataSource(shp_name) # delete temporary raster if it already exists
tp_ds = mem_driver.CreateDataSource(shp_name) # create a new, empty raster in memory
tp_lyr = tp_ds.CreateLayer('polygons', None, ogr.wkbPolygon) # create a temporary polygon layer
tp_lyr.CreateFeature(p_feat.Clone()) # copy the current feature to the temporary polygon layer
offsets = boundingBoxToOffsets(p_feat.GetGeometryRef().GetEnvelope(),\
geot) # get the bounding box of the polygon feature and convert the coordinates to cell offsets
new_geot = geotFromOffsets(offsets[0], offsets[2], geot) # calculate the new geotransform for the polygonized raster
tr_ds = mem_driver_gdal.Create(\
"", \
offsets[3] - offsets[2], \
offsets[1] - offsets[0], \
1, \
gdal.GDT_Byte) # create the raster for the rasterized polygon in memory
tr_ds.SetGeoTransform(new_geot) # set the geotransfrom the rasterized polygon
gdal.RasterizeLayer(tr_ds, [1], tp_lyr, burn_values=[1]) # rasterize the polygon feature
tr_array = tr_ds.ReadAsArray() # read data from the rasterized polygon
r_array = r_ds.GetRasterBand(1).ReadAsArray(\
offsets[2],\
offsets[0],\
offsets[3] - offsets[2],\
offsets[1] - offsets[0]) # read data from the input raster that corresponds to the location of the rasterized polygon
id = p_feat.GetFID() # get the ID of the polygon feature, you can use a different attribute field
3. Mask input data to polygon zones
At this point we have two concurrent (overlapping) numpy arrays: tr_array and r_array. tr_array has a value of 1 that indicates where the polygon has been rasterized. r_array has the values we want to use to calculate zonal statistics for each polygon.
First, make sure that the input raster exists. Next create a mask array. We want to get data from r_array where it does not contain no-data values and where the corresponding value in tr_array equals 1 (or True).
if r_array is not None:
maskarray = np.ma.MaskedArray(\
r_array,\
maskarray=np.logical_or(r_array==nodata, np.logical_not(tr_array)))
Now we’ll use maskarray to calculate zonal statistics for each polygon feature.
4. Calculate zonal statistics for each polygon extent
Write one more function that takes a number of values as inputs and creates a dictionary of values. Place this function with the others at the top of the zonal statistics script.
def setFeatureStats(fid, min, max, mean, median, sd, sum, count, names=["min", "max", "mean", "median", "sd", "sum", "count"]):
featstats = {
names[0]: min,
names[1]: max,
names[2]: mean,
names[3]: median,
names[4]: sd,
names[5]: sum,
names[6]: count,
names[7]: fid,
}
return featstats
Now, calculate the values from maskarray and pass them to the setFeatureStats function. Only do this if the array exists (is not None). Otherwise, pass the no data value to set the statistics.
if maskarray is not None:
zstats.append(setFeatureStats(\
id,\
maskarray.min(),\
maskarray.max(),\
maskarray.mean(),\
np.ma.median(maskarray),\
maskarray.std(),\
maskarray.sum(),\
maskarray.count()))
else:
zstats.append(setFeatureStats(\
id,\
nodata,\
nodata,\
nodata,\
nodata,\
nodata,\
nodata,\
nodata))
else:
zstats.append(setFeatureStats(\
id,\
nodata,\
nodata,\
nodata,\
nodata,\
nodata,\
nodata,\
nodata))
The Full Zonal Statistics Script
Congratulations! You have created a Python zonal statistics script that can be applied to many different applications. The full script is available below.
import gdal
import ogr
import os
import numpy as np
import csv
def boundingBoxToOffsets(bbox, geot):
col1 = int((bbox[0] - geot[0]) / geot[1])
col2 = int((bbox[1] - geot[0]) / geot[1]) + 1
row1 = int((bbox[3] - geot[3]) / geot[5])
row2 = int((bbox[2] - geot[3]) / geot[5]) + 1
return [row1, row2, col1, col2]
def geotFromOffsets(row_offset, col_offset, geot):
new_geot = [
geot[0] + (col_offset * geot[1]),
geot[1],
0.0,
geot[3] + (row_offset * geot[5]),
0.0,
geot[5]
]
return new_geot
def setFeatureStats(fid, min, max, mean, median, sd, sum, count, names=["min", "max", "mean", "median", "sd", "sum", "count", "id"]):
featstats = {
names[0]: min,
names[1]: max,
names[2]: mean,
names[3]: median,
names[4]: sd,
names[5]: sum,
names[6]: count,
names[7]: fid,
}
return featstats
mem_driver = ogr.GetDriverByName("Memory")
mem_driver_gdal = gdal.GetDriverByName("MEM")
shp_name = "temp"
fn_raster = "C:/pyqgis/raster/USGS_NED_13_n45w116_IMG.img"
fn_zones = "C:/temp/zonal_stats/zones.shp"
r_ds = gdal.Open(fn_raster)
p_ds = ogr.Open(fn_zones)
lyr = p_ds.GetLayer()
geot = r_ds.GetGeoTransform()
nodata = r_ds.GetRasterBand(1).GetNoDataValue()
zstats = []
p_feat = lyr.GetNextFeature()
niter = 0
while p_feat:
if p_feat.GetGeometryRef() is not None:
if os.path.exists(shp_name):
mem_driver.DeleteDataSource(shp_name)
tp_ds = mem_driver.CreateDataSource(shp_name)
tp_lyr = tp_ds.CreateLayer('polygons', None, ogr.wkbPolygon)
tp_lyr.CreateFeature(p_feat.Clone())
offsets = boundingBoxToOffsets(p_feat.GetGeometryRef().GetEnvelope(),\
geot)
new_geot = geotFromOffsets(offsets[0], offsets[2], geot)
tr_ds = mem_driver_gdal.Create(\
"", \
offsets[3] - offsets[2], \
offsets[1] - offsets[0], \
1, \
gdal.GDT_Byte)
tr_ds.SetGeoTransform(new_geot)
gdal.RasterizeLayer(tr_ds, [1], tp_lyr, burn_values=[1])
tr_array = tr_ds.ReadAsArray()
r_array = r_ds.GetRasterBand(1).ReadAsArray(\
offsets[2],\
offsets[0],\
offsets[3] - offsets[2],\
offsets[1] - offsets[0])
id = p_feat.GetFID()
if r_array is not None:
maskarray = np.ma.MaskedArray(\
r_array,\
maskarray=np.logical_or(r_array==nodata, np.logical_not(tr_array)))
if maskarray is not None:
zstats.append(setFeatureStats(\
id,\
maskarray.min(),\
maskarray.max(),\
maskarray.mean(),\
np.ma.median(maskarray),\
maskarray.std(),\
maskarray.sum(),\
maskarray.count()))
else:
zstats.append(setFeatureStats(\
id,\
nodata,\
nodata,\
nodata,\
nodata,\
nodata,\
nodata,\
nodata))
else:
zstats.append(setFeatureStats(\
id,\
nodata,\
nodata,\
nodata,\
nodata,\
nodata,\
nodata,\
nodata))
tp_ds = None
tp_lyr = None
tr_ds = None
p_feat = lyr.GetNextFeature()
fn_csv = "C:/temp/zonal_stats/zstats.csv"
col_names = zstats[0].keys()
with open(fn_csv, 'w', newline='') as csvfile:
writer = csv.DictWriter(csvfile, col_names)
writer.writeheader()
writer.writerows(zstats)